82. Adatok, adatok mindenhol...

„Az adat az új olaj!”
-Clive Humby-
 A jelenkort sokan aposztrofálják az információs társdalom koraként. Úgy jött el ez az idő, hogy szinte észre sem vettük. Alig két évtizeddel ezelőtt a legfrissebb információforrás a teletext volt – már akinek a TV készüléke rendelkezett ezzel a funkcióval –, az esti híradóban pedig csupa újdonság hangzott el. Ehhez képest mára egy 5-6 órás hír már elavult, ha nem nézünk rá egy portálra ennyi időn keresztül, akkor van olyan bejegyzés, amiről egy az egyben lemaradunk. Információ áramlik felénk mindenhonnan és mindenhol: betűk, képek, hangok formájában; otthon, a buszon, a munkahelyen, a pénztárnál sorban állva. Az okos telefonok velünk tartanak mindenhova, laptop nélkül lényegében nem lehet elvégezni egy egyetemet – viszonyításképpen az első saját masinámat 2005-ben vettem... –, ha pedig valaki nem reagál fél napon keresztül egy e-mailre, akkor türelmetlenkedni kezdünk.
A jelenkort sokan aposztrofálják az információs társdalom koraként. Úgy jött el ez az idő, hogy szinte észre sem vettük. Alig két évtizeddel ezelőtt a legfrissebb információforrás a teletext volt – már akinek a TV készüléke rendelkezett ezzel a funkcióval –, az esti híradóban pedig csupa újdonság hangzott el. Ehhez képest mára egy 5-6 órás hír már elavult, ha nem nézünk rá egy portálra ennyi időn keresztül, akkor van olyan bejegyzés, amiről egy az egyben lemaradunk. Információ áramlik felénk mindenhonnan és mindenhol: betűk, képek, hangok formájában; otthon, a buszon, a munkahelyen, a pénztárnál sorban állva. Az okos telefonok velünk tartanak mindenhova, laptop nélkül lényegében nem lehet elvégezni egy egyetemet – viszonyításképpen az első saját masinámat 2005-ben vettem... –, ha pedig valaki nem reagál fél napon keresztül egy e-mailre, akkor türelmetlenkedni kezdünk.
Nem csak fogyasztjuk azonban a minket körülvevő adatrengeteget, hanem igen aktívan hozzá is járulunk növekedéséhez: feltöltünk, megosztunk, fényképezünk – ugye megvan még mindenkinek az az idő, amikor egy komplett nyaralás ráfért két tekercs filmre, és mégsem születtek tömegével rossz képek? - hozzászólunk, írunk, küldünk. A kimutatások szerint az emberiség egyetlen nap leforgása alatt 2,5 milliárd (nem elütés: milliárd...) gigabyte adatot termel! Ez nagyságrendileg egymillió külső merevlemezt töltene meg. Az persze nagy kérdés, hogy ennek mekkora része hordoz érdemi információt bárki számára is, de mindettől függetlenül az adatmennyiség létezik és nőttön-nő.
Ahogy később látni fogjuk, ebben a bankszámlák, genetikai kódok és a Higgs-bozonhoz vezető mérési eredmények mellett a macskás Facebook posztokat, like-okat és smiley-kat is magába foglaló adattengerben néha olyan információ rejlik, amelyre nem is gondolnánk. Még csak most tanuljuk azokat a módszereket, amelyekkel rábukkanhatunk az érdekes összefüggésekre, az adatóceán mélyén megbúvó különös lényekre és azok felhasználási lehetőségeire. Az élet minden területét érinti ez a változás: hangzatos jelszóval élve beköszöntött a „Big Data”, vagyis a „Nagy Adat” korszaka, amely sokak szerint az Internet megjelenésével összemérhető erejű átalakulásokat hoz majd már most. De mit is jelent pontosan az, hogy „nagy”? Mennyi 2,5 milliárd Gb? Milyen iramban bővül a világon meglévő információ mennyisége? Elsőként ezekről a kérdésekről lesz szó!
/Az írás alapjául Patrice Koehl UC-Berkeley-n elhangzott, alább megtekinthető előadásának első fele szolgált./
Ma már minden információt digitalizálunk. Amit véletlenül nem, arról is meg tudjuk állapítani, hogy mekkora adatmennyiség formájában lehetne mégis megtenni. A digitális információ alapegysége a bit. Ez tulajdonképpen egyetlen „kapcsoló”, melynek két értéke van: 0 vagy 1. Maguk a bitek az egyszeri felhasználó elől jobbára rejtve maradnak, a számítógépek azonban élénk érdeklődést mutatnak irántuk. Számukra a világ bitek, vagyis nullák és egyek sorozataként áll elő.
8 bit formál egy byte-ot. Ez az az egység, amely már mindenki számára értékelhető információt jelent: például egy karaktert vagy egy számot. A byte szintjén túllépve sorra érkeznek az újabb és újabb előtagok: kilo-, mega-, giga-, terrabyte, stb. Mindegyik 1024-et jelent az előző egységből. Valahol a giga környékén azonban elveszítjük a fonalat, és kezdenek nehezen értelmezhetővé válni a számok. Próbáljuk meg szemléletessé tenni őket!
Kilobyte (1024 byte)
Ebbe a nagyságrendbe tartoznak az írott szövegek: egy gépelt oldal nagyjából 30 KB.
Megabyte (1024 kilobyte)
Tipikus példa egy popsláger mp3 formátumban. Egy átlagos hosszúságú nóta 4-5 MB nagyságú fájlként tárolható. Felderenghetnek ködös emlékek az első otthoni számítógépekről úgy a 90-es évek közepéről, melyek akár már 128 MB-os merevlemezzel is rendelkezhettek (rajtuk olyan játék legendákkal, mint a Scorch). Azt hittük soha nem telnek meg...
Gigabyte (1024 megabyte)
Beléptünk a mozgóképek birodalmába. Egy hagyományos, nézhető felbontással digitalizált film foglal hozzávetőlegesen ennyi helyet.
Terabyte (1024 gigabyte)
Ez egy átlagosnak mondható mai külső merevlemez mérete. Rendszerint filmekkel, képekkel tömjük tele őket, de a nagyságrendet talán jobban érzékelteti az, ha a hagyományos, írott információforrásokhoz viszonyítjuk azt: kb. 6 millió könyvet tárolhatnánk 1 TB segítségével. Ez azt jelenti, hogy becslések szerint a világ összes megjelent könyve – kiadásonként egy példányról beszélünk - ráférne úgy 25 TB-ra.
Azt hihetnénk, hogy valahol itt véget is ér a skálázás – az otthoni felhasználás szempontjából mindenképpen –, pedig még csak most lendülünk bele igazán. Gondoljunk csak bele: ha a családi nyaralásokhoz terabyte-nyi tárolókapacitásra van szükség, akkor mivel szembesülhet a Google vagy az Amazon?

Petabyte (1024 terabyte)
Nehezen megfogható szám. Ha 1 PB-nyi adatot DVD-kre írnánk ki, akkor azokból a BME udvarán felépített torony csúcsa a Gellért-hegyével lenne egy magasságban: 55 emeletnyi DVD-ről beszélünk.
Exabyte (1024 petabyte)
A világtörténelem kezdetétől 2003-ig számítva az emberiség által megtermelt összes információ mennyisége 5 EB. Más megközelítést alkalmazva: ha 1 byte 1 másodpercnek felelne meg, akkor 1 EB már kétszer több időt jelentene, mint az univerzum kora.
Adódik a kérdés: tényleg van értelme még egy újabb előtagnak (az eddig csendben figyelő helyesírási ellenőr is elkezdett tiltakozni az exabyte kifejezés láttán)? 2003 nem volt olyan régen...
Zettabyte (1024 exabyte)
De, bizony 2003 információs szempontból borzasztó régen volt. A csak 2011-ben létrejött adatmennyiség 1.8 zettabyte. Igen, 2011-ben egyetlen esztendő leforgása alatt 368-szor annyi adat keletkezett, mint a kovakő feltalálása és a Spirit és Opportunity roverek Marsra indítása közt.
Yottabyte (1024 zettabyte, de ki is írjuk: 1208925819614629174706176 byte)
A példa egyben szemléletes, ijesztő és jövőbe mutató is: az NSA – az Amerikai Egyesült Államok botrányba keveredett Nemzetbiztonsági Hivatala – által idén év végén átadásra kerülő új adatközpont Utahban 1 yottabyte-nyi adat tárolására lesz alkalmas.
Ezzel a skála végére értünk, de kérdés, hogy meddig lesz elegendő a jelenlegi lista. A bővülés ütemét nézve nem olyan sokáig. A „Nagy Adat” korszaka, a zettabyte-ok világa vitathatatlanul itt van. A „Nagy Adat” azonban nem csak mennyiséget, hanem sebességet is jelent. Ma egyetlen perc leforgása alatt a világon 204 millió e-mailt küldenek, 3 millió Google keresést hajtanak végre, 6 millióan vannak jelen a Facebookon, 30 órányi videót töltenek fel a Youtube-ra és a Large Hadron Collider 50 GB mérési eredményt generál... Mindössze egyetlen perc alatt történik mindez.  Mit lehet kezdeni ezzel a hihetetlen adatmennyiséggel? Mindig is tudott volt, hogy az információ érték. A cikk elején szereplő idézet olajos hasonlata azonban nem csak ebből a szempontból állja meg a helyét. A nyers adathalmazt ugyanis a nyersolajhoz hasonlóan előbb finomítani kell ahhoz, hogy felhasználhatóvá váljon, hogy ténylegesen információvá lényegüljön át. Ebben rejlik korunk egyik nagy kihívása: az adatok asztronómiai mennyisége már a kezünkben van, de szükségünk van olyan új módszerekre algoritmusokra, rafinált kódokra, amelyek képesek átrágni magukat a byte-ok dzsungelén meglelve azokat az összefüggéseket, amelyekre igazán kíváncsiak vagyunk. A helyzetet bonyolítja, hogy sokszor úgy kell megtalálni valamit, hogy nem is tudjuk igazán mit keresünk... Olyan jelenségeket ismerhetünk fel, amelyekről eddig fogalmunk sem lehetett a megfelelő információk hiányában. A lehetséges összefüggések komplexitása bámulatos, hiszen nem csak az adatmennyiség, de vele együtt a kezelendő lehetséges változók száma is növekszik, egyre nagyobb feladat elé állítva az egyre intelligensebb algoritmusokat. (Ezen a ponton elkanyarodhatnánk a mesterséges intelligencia irányába, de az egy másik témakör.)
Mit lehet kezdeni ezzel a hihetetlen adatmennyiséggel? Mindig is tudott volt, hogy az információ érték. A cikk elején szereplő idézet olajos hasonlata azonban nem csak ebből a szempontból állja meg a helyét. A nyers adathalmazt ugyanis a nyersolajhoz hasonlóan előbb finomítani kell ahhoz, hogy felhasználhatóvá váljon, hogy ténylegesen információvá lényegüljön át. Ebben rejlik korunk egyik nagy kihívása: az adatok asztronómiai mennyisége már a kezünkben van, de szükségünk van olyan új módszerekre algoritmusokra, rafinált kódokra, amelyek képesek átrágni magukat a byte-ok dzsungelén meglelve azokat az összefüggéseket, amelyekre igazán kíváncsiak vagyunk. A helyzetet bonyolítja, hogy sokszor úgy kell megtalálni valamit, hogy nem is tudjuk igazán mit keresünk... Olyan jelenségeket ismerhetünk fel, amelyekről eddig fogalmunk sem lehetett a megfelelő információk hiányában. A lehetséges összefüggések komplexitása bámulatos, hiszen nem csak az adatmennyiség, de vele együtt a kezelendő lehetséges változók száma is növekszik, egyre nagyobb feladat elé állítva az egyre intelligensebb algoritmusokat. (Ezen a ponton elkanyarodhatnánk a mesterséges intelligencia irányába, de az egy másik témakör.)
Mindez egy alapvető, mélyről jövő szemléletbeli változáshoz vezet. Az adatokból értelmezésük útján ismeret keletkezik, mely azután optimális esetben a társadalom hasznára válik. Ezen a transzformáción dolgoznak a kutatók amióta világ a világ. Eddig azonban a tudás megszerzése hipotézisek útján történt: néhány megfigyelés alapján kreáltak egy elméletet, melynek érvényességét utána alaposan megvizsgálták kísérletek segítségével, és szükség esetén finomították vagy éppen elvetették őket. A hipotézis alapú megközelítést azonban egyre inkább felváltja az adat alapú kutatás: sok esetben nincs szükség előzetes feltevésre, „csak” megfelelő módon, megfelelően hosszú ideig kell vizsgálni a szinte végtelen rendelkezésre álló adattengert, és az annak mélyéről felszínre bukkanó összefüggések formájában előáll a hasznos ismeret.
Egy példával illusztrálnánk ezt az elsőre talán nehezen befogadható gondolatot. A BBC „The age of Big Data” című dokumentumfilmjében a Los Angeles egyik körzetében zajló rendőri munkát mutatják be elsőként.
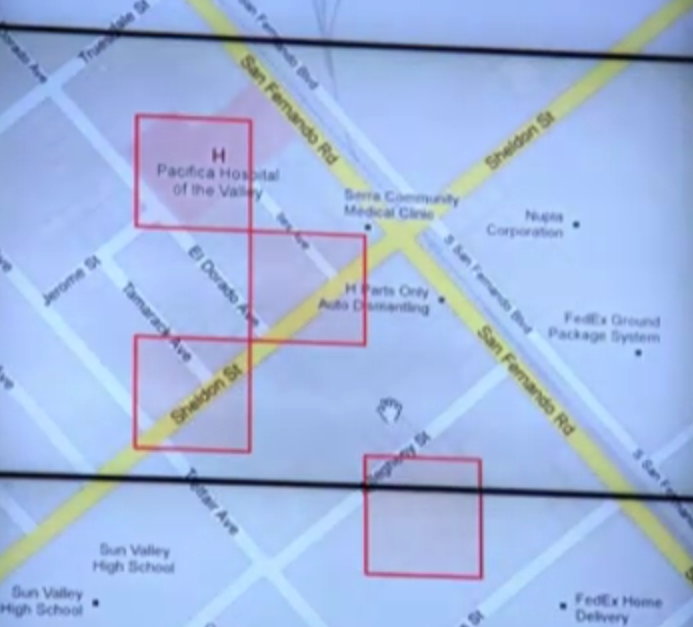 Egy matematikus az előrejelezhetetlen földrengéseket kísérő nagyon is kiszámítható – és modellezhető – utórengések analógiájára kezdett el gondolkodni a bűnesetek előrejelzésén... Sokaknak alighanem a Különvélemény című film ugrik be, pedig szó sincs látnokokról, hacsak nem tekintjük annak az emberi kéz által programozott algoritmusokat. A rendőrségi adatbázis évtizedekre visszamenőleg tárolja a különböző bűneseteket. Ezt az adatbázist kezdte el vizsgálni a kutatócsoport, mely végül előállt egy algoritmussal, amely a megtörtént bűntények mintázata alapján minden nap elkészít egy előrejelzést, amelyben kiemeli az előző napok eseményei és a múltbeli tapasztalatok alapján az adott napon kiemelt kockázatúnak minősülő helyeket. A járőrök kézhez kapták a kockázatos zónákat jelölő térképeket – hangsúlyozzuk: nem arról van szó, hogy bejelölték a köztudottan balhés utcasarkokat, hanem naponta frissítették az előrejelzést az események tükrében -, és napi rutinjuk csak annyival módosult a szokásoshoz képest, hogy az adott térségeket jóval gyakrabban érintették a menetrendszeri cirkálás közepette. Az eredmény megdöbbentő: a körzet egész Los Angelesben a legnagyobb mértékben javította a statisztikáit. 26%-al csökkent a rablások száma, 12%-al a vagyontárgy ellen elkövetett bűncselekmények mennyisége... A sikeren felbuzdulva az egész városra kiterjesztették a programot, és egyre több község veszi azt át.
Egy matematikus az előrejelezhetetlen földrengéseket kísérő nagyon is kiszámítható – és modellezhető – utórengések analógiájára kezdett el gondolkodni a bűnesetek előrejelzésén... Sokaknak alighanem a Különvélemény című film ugrik be, pedig szó sincs látnokokról, hacsak nem tekintjük annak az emberi kéz által programozott algoritmusokat. A rendőrségi adatbázis évtizedekre visszamenőleg tárolja a különböző bűneseteket. Ezt az adatbázist kezdte el vizsgálni a kutatócsoport, mely végül előállt egy algoritmussal, amely a megtörtént bűntények mintázata alapján minden nap elkészít egy előrejelzést, amelyben kiemeli az előző napok eseményei és a múltbeli tapasztalatok alapján az adott napon kiemelt kockázatúnak minősülő helyeket. A járőrök kézhez kapták a kockázatos zónákat jelölő térképeket – hangsúlyozzuk: nem arról van szó, hogy bejelölték a köztudottan balhés utcasarkokat, hanem naponta frissítették az előrejelzést az események tükrében -, és napi rutinjuk csak annyival módosult a szokásoshoz képest, hogy az adott térségeket jóval gyakrabban érintették a menetrendszeri cirkálás közepette. Az eredmény megdöbbentő: a körzet egész Los Angelesben a legnagyobb mértékben javította a statisztikáit. 26%-al csökkent a rablások száma, 12%-al a vagyontárgy ellen elkövetett bűncselekmények mennyisége... A sikeren felbuzdulva az egész városra kiterjesztették a programot, és egyre több község veszi azt át.
Ez a sok szempontból extrémnek mondható példa jól mutatja az adatok elemzésében rejlő lehetőségeket. Ki gondolta volna, hogy olyan látszólag teljesen független események is mintázatokba rendeződhetnek, mint a különböző bűntények egy városrészben. Az elkövetőket rengeteg tényező befolyásolhatja: az előző napi rendőri jelenlét, egy rivális banda megtorlásától való félelem, egy új drog terjedése sarokról-sarokra, stb. A változók száma gyakorlatilag végtelen, de mindezek eredményeként egy szabad szemmel nem látható, az algoritmusok által fellelhető, statisztikailag értelmezhető mintázat áll elő. Egy előrejelzést szolgáló, képletekbe öntött matematikai modellt nyilvánvalóan lehetetlen lett volna papírra vetni egy íróasztal mellett gondolkodva a törvényszerűségeken.
A további cikkekben még számos példával fogunk találkozni. Külön figyelmet szentelünk majd az orvostudomány „Nagy Adat” következtében történő átalakulásának. Azt azonban már az eddig elhangzottak alapján is leszögezhetjük: új lehetőségek nyíltak meg, melyek új eszközöket, új fajta tudást kívánnak. Nagy-Britanniában elemzők véleménye szerint nagyjából 70000 szakemberre lenne szükség „Big Data” témakörben, míg az USA-ban az igényt százezresre becsülik (a kérdéssel részletesebben foglalkozott a Futurista blog). A hirtelen változás következtében az egyetemek még ugyan nem specializálódtak, de nagyon úgy néz ki, hogy aki mesterséges intelligencia, adatbányászat, optimalizálás, matematika, statisztika témakörben mélyed el, az nem tesz rossz lóra. Küszöbön áll az az időszak, amikor az általános társadalmi megítélés szerint is „cool” lesz matematikusnak lenni...
|
Források |
|
Ha tetszett a bejegyzés, és szeretnél frissen értesülni az újakról, illetve szívesen olvasnád azokat az írásokat is, melyeket csak ajánlunk, de külön bejegyzéssé nem érnek (vagy nincs szükség kiegészítésükre), vagy a megnéznéd a tudomány világából származó képeket és a hozzájuk kapcsolódó minibejegyzéseket, akkor csatlakozz a blog Facebook oldalához a jobb hasábban megtalálható alkalmazás segítségével, vagy csak nézd meg azokat az ugyanott található linkekre kattintva (FB regisztráció nélkül is elérhetőek)! Ha pedig szívesen bemutatnád saját szakterületedet, kutatási témádat, vagy blogunk profiljába illő érdeklődési körödet, akkor írj a jobb oldalon megadott e-mail címre! Nagyon nagy örömmel adnánk helyt magyar egyetemeken tevékenykedő kutatócsoportok munkásságáról szóló beszámolóknak! |