83. Big Data és DNS: az orvostudomány forradalma

 Az előző „Nagy Adat”-tal foglalkozó cikkünkben megvizsgáltuk a kérdést, hogy tulajdonképpen mit is értünk „nagy” alatt. Elidőztünk a peta- és zettabyte-ok világában, és rácsodálkoztunk arra a már-már nyomasztó tényre, hogy 2011-ben egyetlen esztendő leforgása alatt 368-szor annyi adat keletkezett, mint az emberiség történetének kezdete és 2003 közt. A mennyiség tehát adott, és napjainkban 24 óránként újabb 2,5 milliárd gigabyte-tal járulunk hozzá a bithalmaz gyarapodásához.
Az előző „Nagy Adat”-tal foglalkozó cikkünkben megvizsgáltuk a kérdést, hogy tulajdonképpen mit is értünk „nagy” alatt. Elidőztünk a peta- és zettabyte-ok világában, és rácsodálkoztunk arra a már-már nyomasztó tényre, hogy 2011-ben egyetlen esztendő leforgása alatt 368-szor annyi adat keletkezett, mint az emberiség történetének kezdete és 2003 közt. A mennyiség tehát adott, és napjainkban 24 óránként újabb 2,5 milliárd gigabyte-tal járulunk hozzá a bithalmaz gyarapodásához.
Kérdés, hogy mit tudunk kezdeni ezzel, ki tudjuk-e aknázni a szinte korlátlan adatmennyiségben rejlő lehetőségeket, illetve hogy miként változtatja meg mindez a hétköznapjainkat. A bevezető cikkben már megismerkedtünk az adat alapú kutatás fogalmával, és röviden bemutattuk a „Big Data” egy lehetséges hétköznapi – ezzel együtt mégis futurisztikusnak ható - alkalmazását is: a bűnmegelőzésben hatékonyan segédkező algoritmusokat, melyek a múltbéli adatok alapján próbálják előrejelezni a veszélyeztetett zónákat a járőrök számára... nem kevés sikerrel!
A mai bejegyzésünkben a „Nagy Adat” és az orvostudomány/egészségügyi ellátás viszonyát vesszük górcső alá, és remélhetőleg sikerül meggyőznünk róla minden olvasót, hogy forradalmi változások előtt állunk! Mi több, igazából már bennük élünk: az átalakulás észrevétlenül, a felszín alatt játszódik le. Érdemes hát kicsit többet tudni róla!
/Az írás alapjául Patrice Koehl UC-Berkeley-n elhangzott, alább megtekinthető előadásának második fele szolgált (kb. 25:00-tól)./
Noha eddig talán sokan nem gondoltak bele, könnyű belátni: az orvostudomány és a „Nagy Adat” jelenség összefonódása teljesen természetes, elkerülhetetlen jelenség. Hiszen hol lehet nagyobb sűrűségben adatokra bukkanni, mint a saját DNS-ünkben, mely közel 3 milliárd karakter formájában kódolja önnön tervrajzunkat és használati utasításunkat? A DNS-ben kódolt információ határozza meg, hogy sejtjeink milyen proteineket állítanak elő. A proteinek tulajdonképpen szervezetünk, sejtjeink kétkezi munkásai: ha kell építkeznek; ha kell etetik, lélegeztetik a sejtet; ha kell takarítanak. Szinte megszámlálhatatlan típusuk és ellátandó funkciójuk van, mind-mind precízen leírva a DNS-ben. Ha a DNS megsérül, vagy egyes részei pontatlanul kerülnek leolvasásra/másolásra, akkor nem a megfelelő proteinek kerülnek le a sejtekben a futószalagokról, és ezáltal kisebb-nagyobb mértékben felbolydulhat a normális működés. Hasonló ez ahhoz, mintha egy tervrajzba itt-ott belefirkálnánk, esetleg néhány számot átírnánk rajta: lehet, hogy nem okozunk vele túl nagy kárt, de az is elképzelhető, hogy a legyártott eszköz működésképtelenné válik... Nagyon vázlatosan így működnek a genetikai betegségek, illetve azok, amelyek megbabrálják a kódolt tervrajzot. Roppant üdvözítő lenne tehát, ha minél több információt sikerülne gyűjteni a DNS-ünkről: ha minél nagyobb hányadát el tudnánk olvasni, és tudnánk, hogy egyes szakaszai mire valók, változásuk milyen hatást gyakorol a parányi proteingyárakon keresztül az egészségünkre.
Az első lépés tehát az adatok kinyerése, vagyis a DNS elolvasása, a szekvenálás. Ennek alapelvét már bemutattuk, az eljárás fejlődését azonban még nem érzékeltettük. Elöljáróban álljon itt annyi, hogy kevés dolog fejlődik olyan ütemben, mint a genomszekvenálás.
1984-ben egyetlen nap alatt nagyjából egy DNS 300 karakterét lehetett elolvasni. Fáradságos, lassú és költséges munka volt ez, mely még csak nem is kecsegtetett annak lehetőségével, hogy egy szép napon emberi időn belül el lehet jutni a 3 milliárd karakteres mű végére. Új technika kidolgozására volt szükség. Ezt tűzte ki célul a mára már történelemmé vált Human Genome Project 1990-ben. A projekt nem csak eredményes volt, de párját ritkító módon hamarabb célhoz ért és kevesebb pénzbe került, mint azt előzetesen gondolták. Igencsak ritka az ilyen nem csak az állami építkezések, de a tudományos erőfeszítések világában is! A 15 évre tervezett munkafolyamat 4 évvel hamarabb, 2001-ben hozta meg a várva-várt eredményt: 3 milliárd dollár és 11 év után sikerült elolvasni egy teljes emberi genomot!
A költségek elsőre talán csillagászinak hathatnak, de kezeljük helyén a számokat: 3 milliárd dollár nagyjából 700 milliárd forintnak felel meg. Nézzünk párat azokból a dolgokból, amelyek ezzel az összeggel egyenértékűek: a legújabb árfolyamon számítva kb. 200 km magyar autósztráda, 8 új Puskás Stadion, az amerikai hadsereg éves költségvetésének 0,5 %-a, 20 darab F-35A típusú vadászgép, stb. Nem akarunk demagógia terén külön babérokra törni – erős a mezőny, kicsi az esély a kiugró eredményre –, pusztán csak azt kívánjuk érzékeltetni, hogy az elsőre igencsak költségesnek tűnő, az emberiség szempontjából sorsdöntő kutatások, fejlesztések sokszor bizony egyáltalán nem minősülnek extrém drágának relatív skálán mérve...
A kis kitérő után zökkenjünk vissza gondolatunk fő sodrába: joggal merülhet fel a kérdés, hogy miként használható ez az eredmény? 11 évet várni egy orvosi eredményre még a legrosszabb egészségügyi rendszerben is minimum kirívónak minősülne, és valószínűleg a 3 milliárd dollár is kívül esik a felhasználható TB kereten. Mint említettük, kevés dolog fejlődik olyan ütemben, mint a genomszekvenálás: vessünk egy pillantást az alábbi ábrára, melyen egyetlen teljes emberi DNS szekvenálásának költsége látható az idő függvényében ábrázolva:
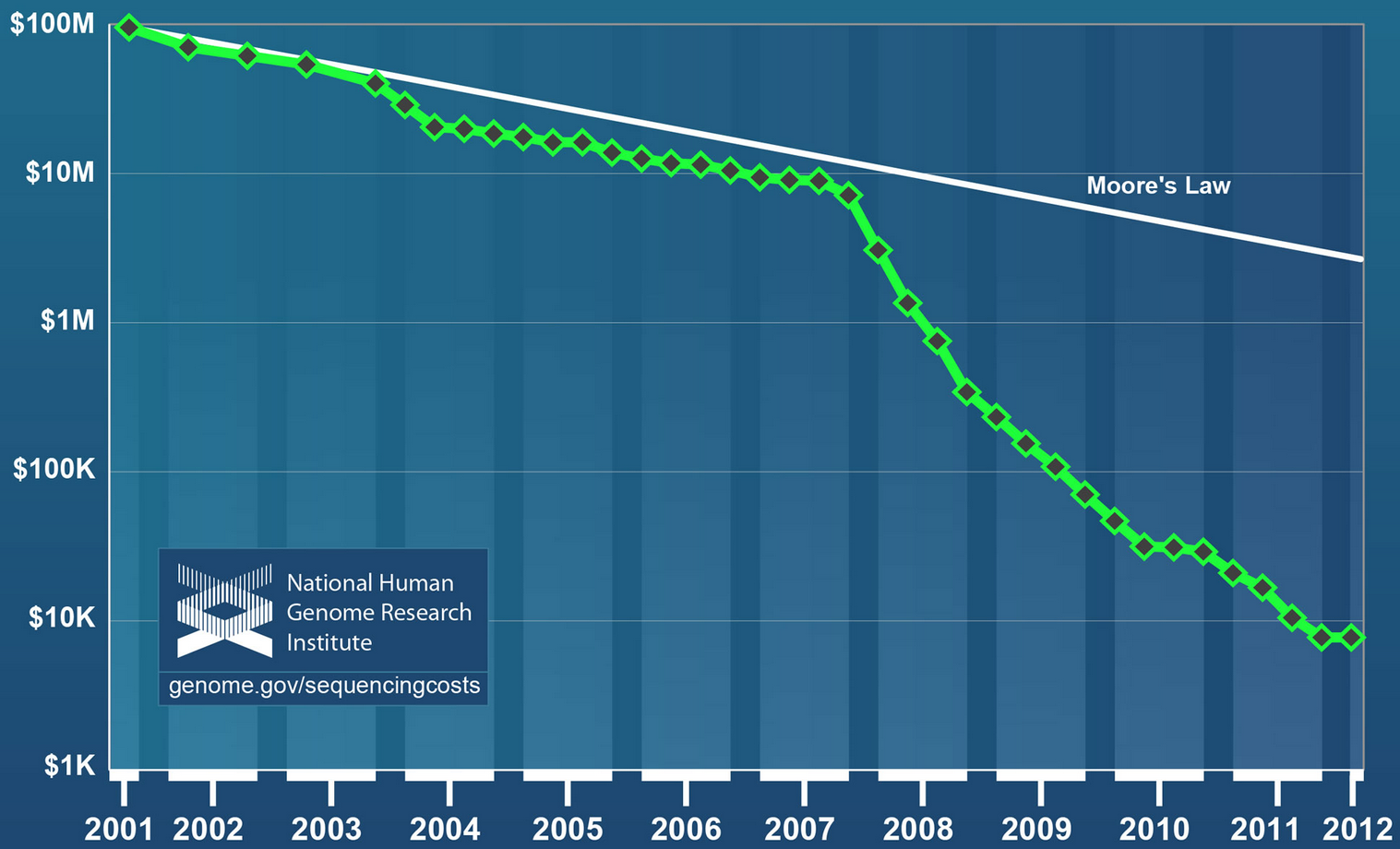
Felhívnánk a figyelmet arra, hogy a függőleges tengely logaritmikus. Míg 2001-ben a költség nagyságrendileg 100 millió dollár volt (a fentebb emlegetett 3 milliárd a projekt teljes költsége volt, melybe beletartozott az új eljárások, berendezések kifejlesztése is), addig ez az érték 2007-re tizedére csökkent, jelenleg pedig valahol a 3-4000 dollár környékén jár... Az előrejelzések szerint 3-4 éven belül egy emberi genom elolvasása összesen 10 dollárba (!!!) fog kerülni. Alig 15-20 évvel az eljárás kidolgozása után. Ha minden új termék ára ilyen ütemben csökkenne, akkor ma nagyon kevés dologért kéne egyáltalán bármilyen összeget is fizetnünk...
Gondolhatnánk, hogy ez a hihetetlen fejlődés a számítógépeink képességeinek bővülésével párhuzamosan, azzal egy ütemben történik. A valóság azonban az, hogy nem csak erről van szó. Moore híres tapasztalati törvénye kimondta, hogy az integrált áramkörökön található tranzisztorok száma kétévente megduplázódik. Hasonlóképpen változott a számítási kapacitás, az elérhető memória mennyisége, de még a digitális kamerák pixelszáma is. Ha elvonatkoztatunk a tranzisztoroktól, és ehelyett pusztán a különböző „számítógépek” által elvégzett, egységnyi költségre vetített műveletek számát vizsgáljuk, akkor azt kapjuk, hogy ez a mutató évente duplázódik:
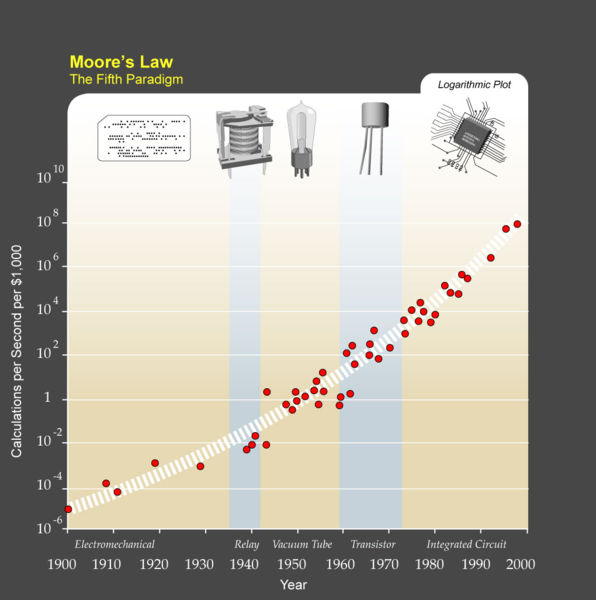
Visszatérve a szekvenálás költségére: a korábbi ábrán egy fehér egyenes jelképezi azt a költségcsökkenési ütemet, amelyet pusztán a számítógépek adott idő alatt végbemenő fejlődése indokolna. Látható, hogy hatalmas az eltérés, mindez az újabb és újabb szekvenálási eljárások kidolgozásának köszönhető. A költségek tehát rohamosan csökkennek, de az egészségügy szempontjából ez önmagában mit sem érne, ha éveket kellene várni az eredményre. A szekvenálás sebessége tehát legalább annyira fontos paraméter, mint az ára.  Nem kell csalódnunk: ezen a területen is észvesztő a fejlődés. A ma legmodernebbnek számító Illumina HiSeq típusú készülékek egészen elképesztő ütemben ontják magukból a genetikai kódokat. Ahogy arra Gary Schroth, az Illumina kutatója rámutatott: egyetlen labor egyetlen szekvenáló berendezéssel ma 4 nap alatt több genetikai kódot képes szekvenálni, mint amennyit összesen a GenBank adatbázisában tároltak 2009-ben... Még ha lassabb – ezáltal pontosabb - üzemmódban is használják az eszközt, egy teljes emberi genom szekvenálása akkor sem tart tovább 2 hétnél.
Nem kell csalódnunk: ezen a területen is észvesztő a fejlődés. A ma legmodernebbnek számító Illumina HiSeq típusú készülékek egészen elképesztő ütemben ontják magukból a genetikai kódokat. Ahogy arra Gary Schroth, az Illumina kutatója rámutatott: egyetlen labor egyetlen szekvenáló berendezéssel ma 4 nap alatt több genetikai kódot képes szekvenálni, mint amennyit összesen a GenBank adatbázisában tároltak 2009-ben... Még ha lassabb – ezáltal pontosabb - üzemmódban is használják az eszközt, egy teljes emberi genom szekvenálása akkor sem tart tovább 2 hétnél.
A „Nagy Adat” jelensége tehát nagyon is jelen van. Kész vagyunk hát? Elégedetten hátradőlhetünk és lezárhatjuk az ilyen irányú kutatásokat? Nem ilyen egyszerű a helyzet: olvasni ugyan megtanultunk, de a szövegértés terén még bőven van hova fejlődni. Míg egy évtizeddel ezelőtt a DNS analízis költségének 80%-át maga a szekvenálás jelentette, addig most ez csak parányi töredéke a kiadásoknak a fentebb vázolt tendenciáknak köszönhetően. A költségek 60%-át ma az adatok feldolgozása adja. Ne felejtsük el, a szekvenáló berendezés a véletlenszerűen apró darabokra szabdalt DNS rövid szakaszait határozza csak meg, ezt követően hátra van még a már meghatározott szegmensek összeillesztése (lásd: a szekvenálásról szóló írásunkat), a hibák kijavítása, stb. A költségek átrendeződésénél is drámaibb az adatok megszerzésére és értelmezésére fordított idő aránya. Egy fenyőfa genomja például alig 4 nap alatt szekvenálható, ennyi idő szükséges a kis DNS szakaszok meghatározásához, a nyers adatsor előállításához. Ezt követi a feldolgozás folyamata, amely majd 3 hónapot vesz igénybe. (Egy egyszerű hasonlattal élve: egy új LEGO készletet nem tart sokáig kicsomagolni, de attól, hogy előttünk van az asztalon az összes szükséges elem, még igen sok időbe is beletelhet, mire összerakjuk az adott masinát.)
A kihívást tehát nem a nyers adatok előállítása jelenti, hanem azok feldolgozása: ez a „Nagy Adat” korszakának egyik legfontosabb, általános jellemzője, ez jelöli ki a legújabb kutatási irányokat. Olyan területek fejlesztése vált égetően fontossá, amelyek a ránk zúduló adatlavina előtt koránt sem tűntek ennyire fontosnak, hiszen a rendelkezésre álló eszközök is elegendőnek bizonyultak céljaink eléréséhez. Magabiztosan kezeltük az 5-10 cm-es havazásokat egy hólapáttal a kezünkben, de mindez már nem elég, ha egyszer csak minden éjjel 3 méteres lepel borítja be a kocsibejárót...
A még mindig jelen levő kihívások mellett is kijelenthetjük: a jelenlegi tendenciák szerint 5 év múlva alig 90 milliárd dollárból (a világ 20 nap alatt költ el ennyi pénzt katonai célokra...) az összes ember génállományát meg lehetne határozni nem is olyan hosszú idő alatt. Mit jelent mindez az alkalmazások szempontjából?
Egyrészt a diagnosztika teljes megújulását (a videón 43:30-tól). A hagyományos eljárás szerint a betegnek vélt szövetből mintát vesznek, majd a sejteket a megfelelő módon tenyésztik, és különböző módszerekkel vizsgálják őket, összehasonlítva elváltozásaikat a korábbi tapasztalatokkal, a rendelkezésre álló könyvtárakkal. Most – nem a jövőben, hanem már ténylegesen ezekben a percekben is – lehetőség van arra, hogy egy vérvételt követően elolvassák a páciens DNS-ét, és abból következtessenek arra, hogy mely proteinek termelése vagy működése tér el az elvárttól. Itt arról van tehát szó, hogy a betegség tüneteinek – úgy mint a sejtek elváltozása – megfigyelése helyett közvetlenül annak okait lehet vizsgálni a DNS szintjén, az adott páciensre szabott módon. Ez a váltás különösen gyümölcsöző lehet a rákos megbetegedések ellen folytatott küzdelemben. Egy újabb lökés mindez a személyre szabott orvostudomány fejlődésének az őssejttechnikában rejlő lehetőségek mellet (lásd még: a saját sejtjeinkből építhető chip modellekről szóló írásunkat).
Másrészt a betegségek mechanizmusának megértése is könnyebbé válhat: a példának okáért rákos sejtek DNS-e eltárolható, így a világ összes páciensének leleteiből egy olyan adatbázis hozható létre, amelynek analizálásával korábban soha észre nem vett mintázatok rajzolódhatnak ki, esetleg utat mutatva a lehetséges gyógymódok felé. Jelenleg DNS-ünk alig 1%-áról tudjuk, hogy mire való, így bőven van még mit megismerni. A középkor nagy felfedezői félelmet nem ismerve haladtak az ismeretlen fehér foltok felé. A mai kor felfedezőinek egyszerűbb a dolga: a modern technika vívmányainak hála kezükben ott van a térkép, csak meg kell tanulni értelmeni azt.
Nem vitás, egy új korszak hajnalán járunk, és az elkövetkezendő években rengeteg újdonság vár ránk. Ezekből sokat talán észre sem veszünk majd, hiszen a kórházak laborjaiban, a szemünktől elzárva végzik majd az elemzéseket, mi „csupán” a pontosabb diagnózisoknak és az egyre több, ma még gyógyíthatatlannak vélt betegség leküzdésének örülhetünk majd, na és persze a kevesebb mellékhatással és kellemetlenséggel járó kezeléseknek.
|
Források |
|
Ha tetszett a bejegyzés, és szeretnél frissen értesülni az újakról, illetve szívesen olvasnád azokat az írásokat is, melyeket csak ajánlunk, de külön bejegyzéssé nem érnek (vagy nincs szükség kiegészítésükre), vagy a megnéznéd a tudomány világából származó képeket és a hozzájuk kapcsolódó minibejegyzéseket, akkor csatlakozz a blog Facebook oldalához a jobb hasábban megtalálható alkalmazás segítségével, vagy csak nézd meg azokat az ugyanott található linkekre kattintva (FB regisztráció nélkül is elérhetőek)! Ha pedig szívesen bemutatnád saját szakterületedet, kutatási témádat, vagy blogunk profiljába illő érdeklődési körödet, akkor írj a jobb oldalon megadott e-mail címre! Nagyon nagy örömmel adnánk helyt magyar egyetemeken tevékenykedő kutatócsoportok munkásságáról szóló beszámolóknak! |